Decepticon red team agent is an open source attempt to turn red team work into an agent workflow rather than a scanner-plus-report routine. The interesting part is not that it can call offensive tools. It is that the project puts rules of engagement, sandbox isolation, and an operation plan in front of the automation.
Table of Contents
The short version
- Decepticon describes itself as an autonomous red team agent for reconnaissance, exploitation, privilege escalation, lateral movement, and command-and-control work.
- The project claims a 102 out of 104 pass rate on the XBOW validation benchmarks, which is useful context but still not a substitute for testing in your own lab.
- Its design separates management services from a Kali Linux sandbox and says commands run inside that sandboxed operational network.
- The product question is less “can an AI hack?” and more “who approves the target, constrains the run, and reads the logs afterward?”
What happened
Purple AI Lab published Decepticon as an Apache-2.0 open source project on GitHub. The repository describes it as an autonomous red team agent that can work across a full attack chain: reconnaissance, exploitation, privilege escalation, lateral movement, and command-and-control.
The README also claims a 98.08% result on the XBOW validation benchmarks: 102 passes out of 104 challenges. That number will draw attention, but the repo’s operating model is the more useful part for security teams. Before activity begins, Decepticon says it generates an engagement package with rules of engagement, concept of operations, a deconfliction plan, and an operation plan mapped to MITRE ATT&CK.
Architecturally, Decepticon separates management services such as LiteLLM, PostgreSQL, LangGraph, and the web interface from the sandbox side where Kali, command-and-control components, and targets live. It also describes 16 specialist agents organized by kill chain phase, with a fresh context window per objective.
Why this is worth watching
Security automation has a different risk profile from code completion or meeting notes. A coding agent can break a test suite. A red team agent can touch a network, run a tool against the wrong host, or leave artifacts that defenders have to explain later.
That is why Decepticon is worth reading even if you never run it. Its docs force a practical checklist: target scope, written authorization, network isolation, tool execution boundaries, prompt and command logs, model fallback behavior, and a human stop button. Those controls are the difference between a useful internal security tool and a liability with a web dashboard.
The broader signal is also clear. AI agent products are moving into jobs where mistakes have real blast radius. For more coverage of agent tools and security-adjacent developer workflows, see the IT & AI archive.
why the Decepticon red team agent matters
The Decepticon red team agent is a good test case for how AI security tools should be judged. A long feature list is not enough. Teams need to know whether the agent can be confined to an approved lab, whether it records each command and decision, and whether operators can interrupt it before a bad assumption turns into traffic on the wire.
The project’s use of specialist agents also raises a product design question. Splitting work by kill chain phase can keep context cleaner, but it can also make accountability harder if the system does not preserve a readable trail. Security teams should ask how the agent chose a path, which tool produced each result, and which human approved the next step.
For app builders and security vendors, this is also an app discovery problem. Agent directories and security marketplaces will need trust markers that ordinary software listings do not capture well: safe defaults, isolated execution, audit export, model provider controls, and clear warnings around authorization.
What the discussion is missing
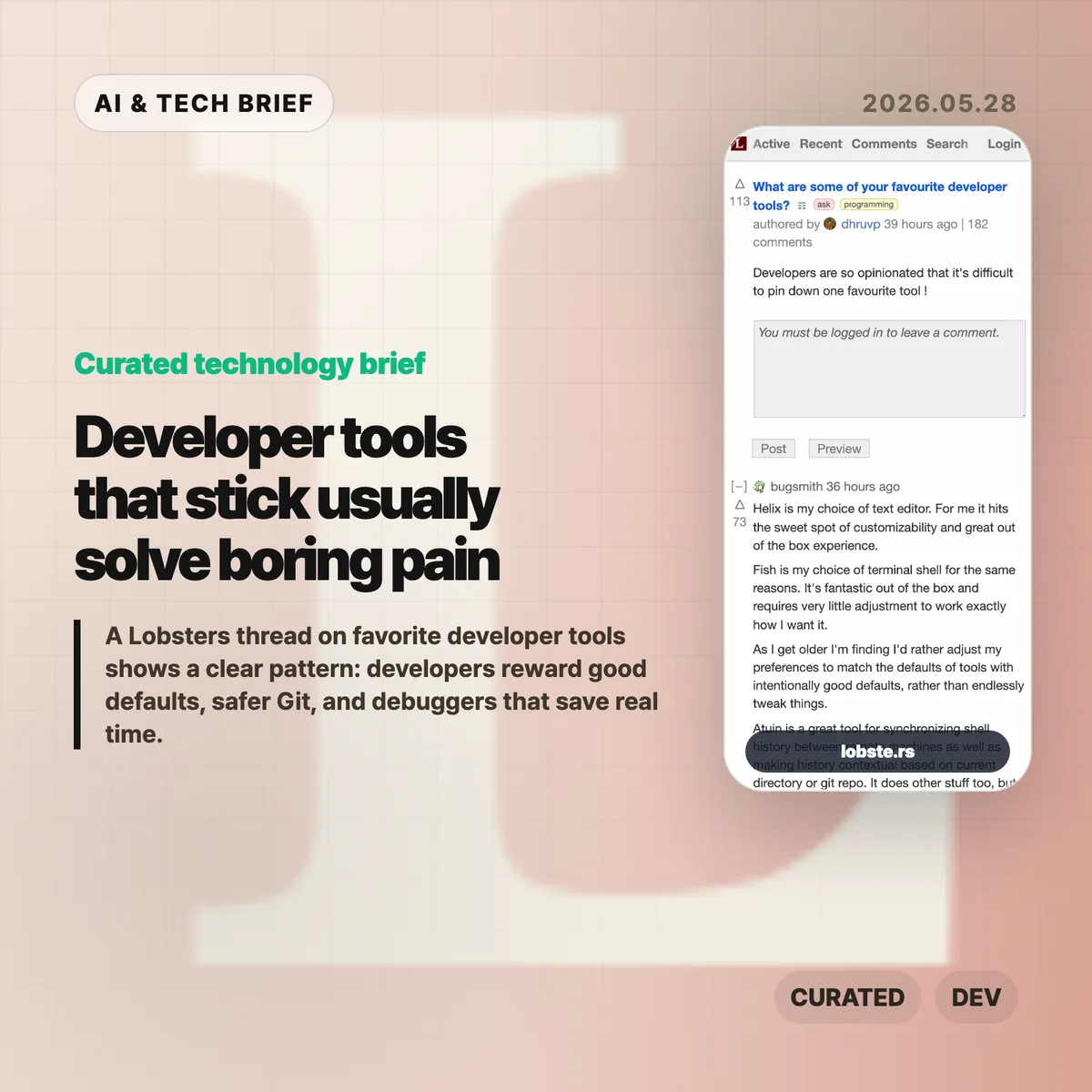
A public Hacker News thread was not available for this brief. The missing discussion is still easy to predict because offensive security automation tends to split readers into familiar camps.
Builders will want to know whether the benchmark claims hold outside curated environments, whether the tool can handle messy interactive shells, and how well it recovers when a scan or exploit path fails. Operators will care more about containment: where credentials live, what traffic can leave the sandbox, how logs are stored, and whether the model can be tricked into stepping outside the engagement plan.
The useful skepticism is not “AI hacking is scary.” It is more specific: any autonomous offensive tool needs proof that its guardrails are harder to bypass than its demo is impressive.
The practical read
Treat Decepticon as a design reference before treating it as an operational tool. If you evaluate it, start in a lab you own, with disposable targets, no production credentials, and a written scope. Then read the logs as closely as the results.
For security teams, the buying or adoption checklist should be boring on purpose: authorization workflow, sandbox boundaries, network egress controls, credential handling, audit retention, model/provider configuration, and rollback steps. If those pieces are unclear, the automation is not ready for real assets.
For AI product teams, the lesson is broader. Once an agent can run terminal commands, cloud tools, or security scanners, product quality depends on operational discipline as much as model quality. The Decepticon red team agent makes that tradeoff visible.