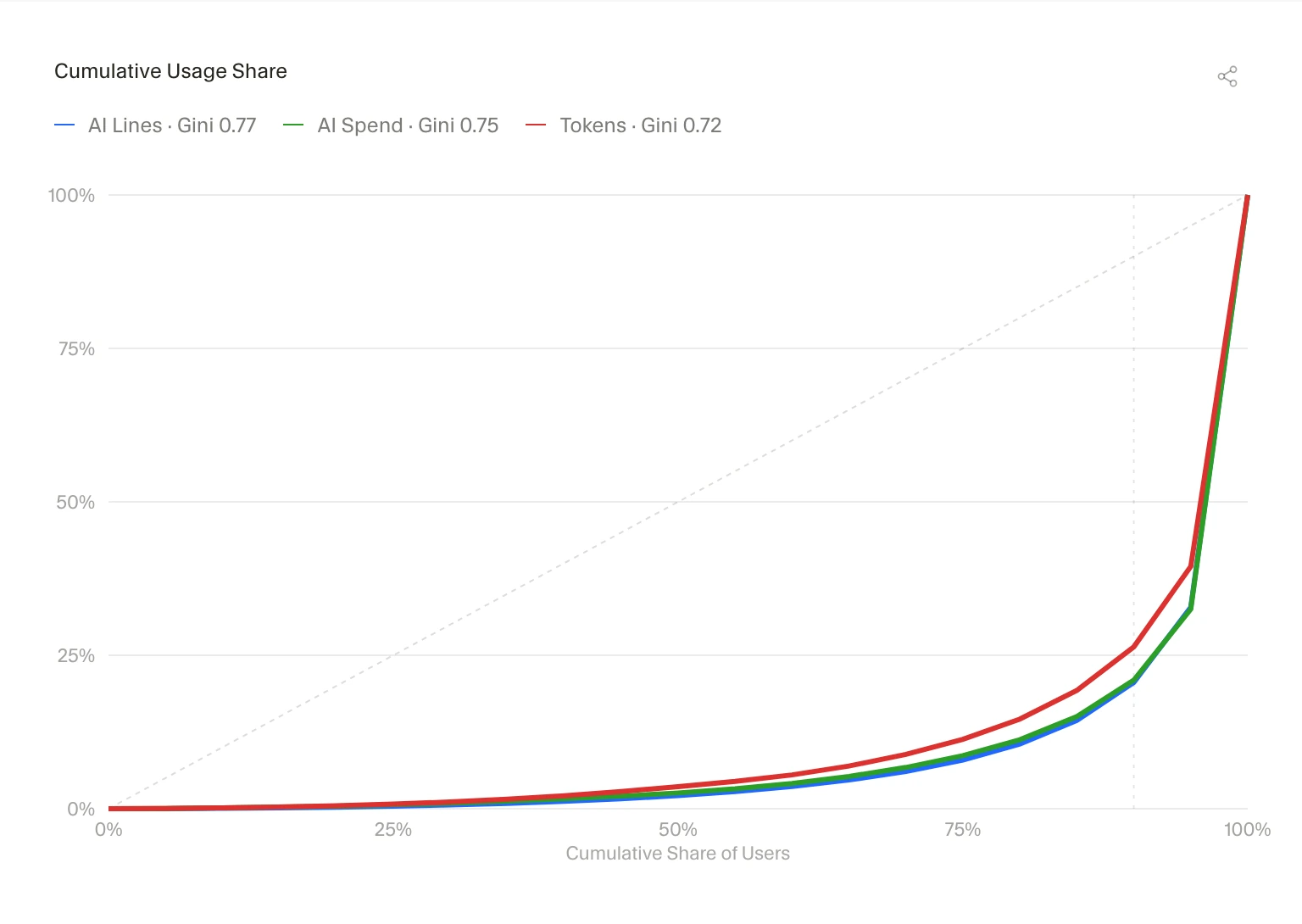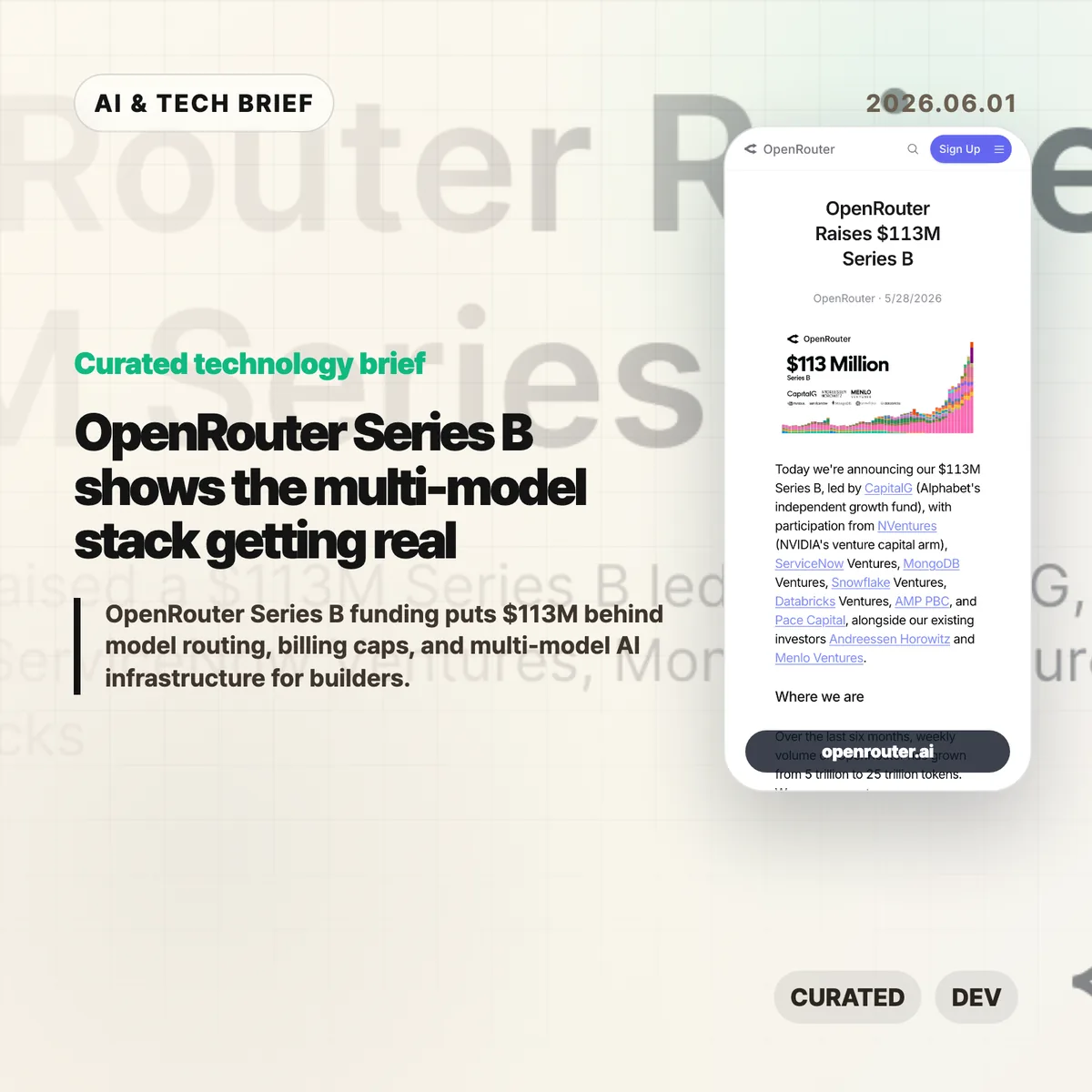
OpenRouter Series B funding puts $113 million behind a simple bet: AI apps will not settle on one model provider. The company says it now serves more than 8 million developers across 400-plus models, with weekly volume growing from 5 trillion to 25 trillion tokens in six months.
Table of Contents
The short version
- OpenRouter raised a $113 million Series B led by CapitalG, with NVentures, ServiceNow Ventures, MongoDB Ventures, Snowflake Ventures, and Databricks Ventures also joining the round.
- The useful part of the OpenRouter Series B announcement is not the valuation story. It is the claim that model routing, billing, failover, and data controls are becoming a real infrastructure layer.
- Developers on Hacker News like the convenience, model coverage, and billing caps, but they are also arguing about the 5% markup, privacy, lock-in, and whether this should be a library instead of a hosted proxy.
- For builders, the decision is practical: use a gateway while experimenting, then decide whether the routing layer is still worth paying for at scale.
What happened
OpenRouter announced a $113 million Series B led by CapitalG. The round also includes NVentures, ServiceNow Ventures, MongoDB Ventures, Snowflake Ventures, Databricks Ventures, Andreessen Horowitz, and Menlo Ventures.
The company describes itself as the layer between AI applications and model providers. Its pitch is routing, reliability, cost optimization, compliance, workspaces, spend controls, guardrails, and zero-data-retention options. That is a different business from selling access to a single frontier model.
The growth numbers are the hook. OpenRouter says weekly volume rose from 5 trillion to 25 trillion tokens over the last six months, and that it is on pace to process more than a quadrillion tokens this year. The company also says more than 8 million developers are building across more than 400 models through the platform.
For more English tech briefs like this, the IT & AI archive tracks the same shift from model launches to the infrastructure around them.
why OpenRouter Series B matters
OpenRouter Series B matters because it points to a boring but important problem inside AI products: model choice is becoming operational work. Teams may want Claude for one task, Gemini or GPT for another, an open model for cost-sensitive traffic, and a specialist model for image, code, or long-context jobs.
That choice gets messy once real users arrive. Each provider has its own API behavior, pricing, rate limits, outage patterns, logging terms, and privacy controls. A model gateway can turn that mess into a single integration, at least in theory.
There is a cost to that convenience. A proxy adds another dependency, another policy surface, and another bill. If the app is small or experimental, that trade may be easy. If the app is moving millions of expensive requests, the markup and data path need a harder look.
Why this is worth watching
The investor list is telling. CapitalG is leading, but the strategic names around the table are enterprise infrastructure companies. ServiceNow, MongoDB, Snowflake, and Databricks all have reasons to care about how companies route AI work across models and data systems.
That does not mean OpenRouter owns the category. Cloudflare, Vercel, Replicate, direct provider APIs, client libraries, and internal gateways all crowd the same space from different directions. The question is whether developers want a neutral marketplace-style router, a cloud vendor gateway, or a small shim they control themselves.
The market is still young enough that the answer may change by workload. A solo builder testing models has different needs from a company with compliance reviews, budget owners, abuse controls, and incident response.
What Hacker News readers are arguing about
The Hacker News thread is useful because it does not read like a victory lap. The strongest positive case is convenience. Developers like being able to try new models without wiring up every provider, and several comments point to consolidated billing, usage limits, and fast model switching as the real value.
The skepticism is just as practical. Some commenters argue that a 5% fee becomes painful when a team is already spending heavily on expensive models. Others ask why this needs to be a hosted company at all when a client library or self-run gateway could normalize provider APIs.
Privacy and data handling come up repeatedly. One camp warns that free or cheap model access may mean prompts and outputs are valuable to someone else. Another points out that OpenRouter offers filters for zero-data-retention providers, which helps but still leaves teams responsible for understanding the full data path.
There is also a scale split. OpenRouter looks attractive for experiments, early products, and teams that value billing caps. At higher volume, several commenters expect serious users to compare the gateway against first-party APIs, internal routing, or alternatives like Cloudflare and Vercel.
The practical read
If you are building an AI app, OpenRouter is easiest to understand as a routing and procurement layer, not as a better model. It can reduce setup time, make model comparisons easier, and give smaller teams controls that some model providers still handle awkwardly.
The practical test is simple. Use a gateway when it speeds up exploration or gives you spend limits you cannot get elsewhere. Revisit the choice once traffic is predictable. At that point, compare total cost, outage behavior, logging policy, privacy terms, and how hard it would be to move away.
For agent products, the routing layer may matter even more. Multi-step workflows are sensitive to latency, failures, and model drift. A gateway can help, but it cannot replace evaluation, monitoring, and clear fallbacks inside the product.