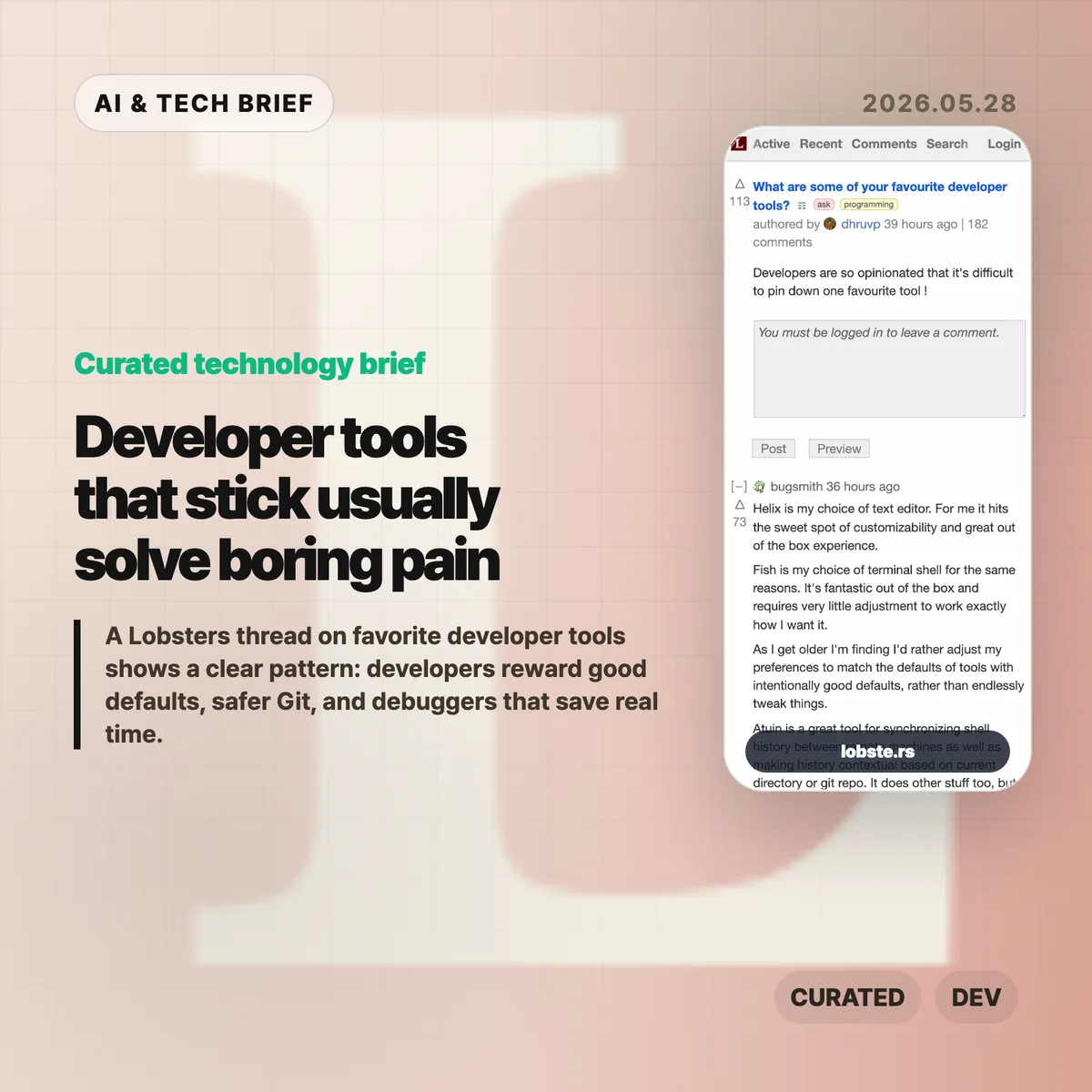
Local AI coding costs are becoming a real budget line for teams that run coding agents all day. A SignalBloom essay argues that cheap open-source models, local inference, and lower-cost engineering labor could put a ceiling on what frontier labs can charge for routine software work. The claim is a little aggressive, but the cost pressure is not imaginary.
Table of Contents
The short version
- The essay compares frontier-model API economics with much cheaper open-source model usage, using a roughly 30x token-cost gap as the headline example.
- Coding agents burn tokens differently from chatbots: they read files, retry commands, inspect logs, and loop through implementation work.
- The strongest case for local AI is not replacing every frontier model call. It is routing boring, repeatable coding tasks to cheaper systems.
- The hard part is quality control. Architecture, product judgment, security review, and long-context debugging still need stronger models or stronger humans.
- For more coverage of AI tools and software economics, see the IT & AI archive.
What happened
SignalBloom published an argument that outsourcing plus LocalAI-style setups may soon look more economical than relying on frontier AI labs for a large share of coding work. The piece frames the issue around price: if frontier model calls keep getting more expensive while open-source models keep improving, teams that run many coding-agent loops will start looking for cheaper routing strategies.
The article cites a large gap between high-end commercial model pricing and DeepSeek-style open model costs, with the headline comparison landing around 30x in favor of the cheaper option. Treat that number as a directional example, not a permanent price table. Model pricing changes quickly, and a token price alone does not include hardware, orchestration, monitoring, review time, or failed attempts.
Still, the basic point is useful. AI coding agents are not one-shot assistants. They may scan a repository, write code, run tests, read the failure, try again, and repeat the loop. That makes local AI coding costs more important than they looked when teams were only comparing chat subscriptions.
Why this is worth watching
The interesting shift is in routing. A team does not have to choose one model for everything. It can use a frontier model for planning, ambiguous debugging, security-sensitive review, or architecture. It can then hand well-scoped implementation chores to cheaper open-source models or local inference when the task is narrow enough.
That is why this story matters for developer-tool companies. Heavy users are already different from casual users. A founder asking a chatbot for a landing-page tweak is not the same customer as a team running ten agents across a monorepo. Once agents become part of the workflow, inference starts to look like cloud spend. You need budgets, limits, queues, caches, and a reason for every expensive call.
The catch is that cheap does not mean free. Local inference brings hardware costs, model-serving work, evaluation, prompt routing, and review burden. Outsourced engineering also adds coordination cost. If the cheaper system produces work that a senior engineer must constantly unwind, the apparent savings vanish fast.
What Hacker News readers are arguing about
The Hacker News thread is more useful than the headline because it pushes on the economics from several angles. One camp buys the basic pressure story: open-source models only need to become good enough for day-to-day software tasks to take revenue away from frontier labs. Several commenters imagined hybrid workflows where a strong model handles planning while cheaper models handle the token-heavy implementation loop.
The main objection is marginal cost. Some readers argued that AI is not like older software, where serving one more user can feel close to free. Inference uses expensive hardware, and the cost curve becomes stepwise: if existing capacity is full, the next user may require another server. That makes price competition more complicated than a simple SaaS comparison.
A second thread focused on energy, chips, and geography. Some commenters thought lower energy costs and more efficient inference infrastructure could favor Chinese labs or local deployment. Others pushed back, noting that training expertise, capital allocation, chip constraints, and regulatory friction still matter.
The practical signal from the discussion is that nobody should model this as a clean replacement story. The believable version is a mixed stack: frontier models where quality pays for itself, cheaper local models where repetition dominates, and humans watching the seams.
The practical read on local AI coding costs
If you run a small team, the move is not to rip out frontier models. Start by measuring where the tokens go. Coding-agent usage often hides the expensive part in repository reads, failed runs, and repeated edits. Once you know that, you can test cheaper models on bounded tasks: test generation, mechanical refactors, migration scripts, documentation updates, and first-pass bug fixes.
Keep the evaluation boring. Compare accepted pull requests, reviewer time, rollback rate, failed test loops, and security findings. If a local model saves 80% on inference but doubles review time, it did not save money. If it handles repetitive changes while the frontier model handles planning, it may be worth keeping.
The bigger lesson is that local AI coding costs will become a product-design constraint. Coding-assistant vendors, agent platforms, and internal tooling teams need pricing that survives power users. The winning stack may be less glamorous than the model leaderboard: good routing, clear budgets, strong review, and enough taste to know when the cheap path is getting expensive.