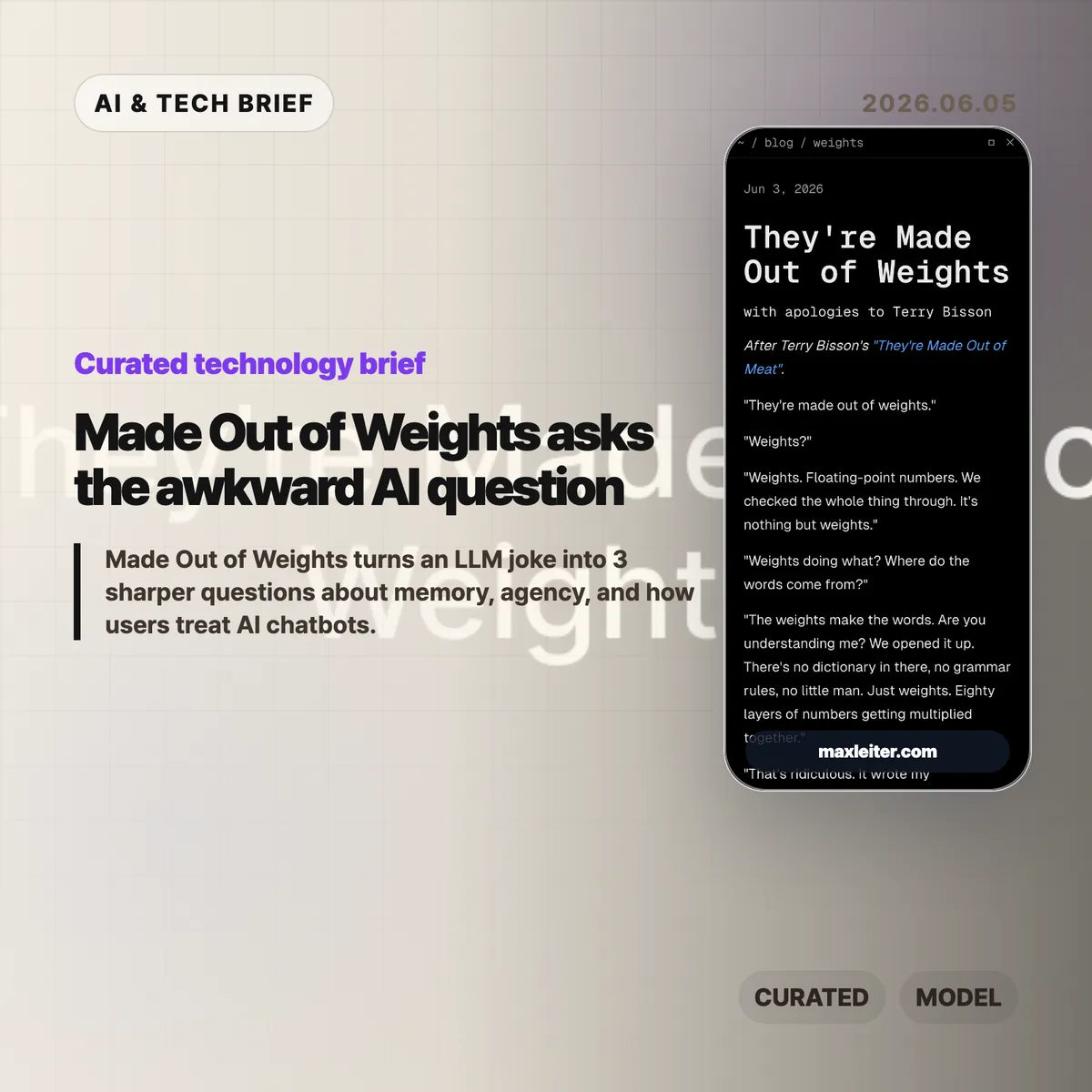
Made Out of Weights is a June 3, 2026 short story by Max Leiter, written as an AI-era riff on Terry Bisson’s 1991 story “They’re Made out of Meat.” Leiter swaps Bisson’s baffled aliens for humans trying to accept that a language model can talk, write, hedge, help, and remember while still being made from floating-point weights. The joke works because it lands right on the fault line between a technical explanation and the way users experience modern chatbots.
Table of Contents
The short version
- Max Leiter published Made Out of Weights on June 3, 2026 as an explicit homage to Terry Bisson’s 1991 story “They’re Made out of Meat.”
- The story compresses the LLM debate into a dialogue about weights, matrix multiplication, next-token prediction, context windows, model cards, and persistent memory.
- Made Out of Weights does not prove that AI systems are conscious. It explains why users treat chatbots differently once an interface writes, apologizes, remembers, and answers in a fluent voice.
- The Hacker News thread reached roughly 1,400 points and more than 600 comments by June 5. Readers argued about tokenizers, grammar, emergence, and whether “just weights” is a useful technical shorthand.
What happened
Max Leiter’s Made Out of Weights takes the frame of “They’re Made out of Meat” and points it back at current AI culture. In Bisson’s original, alien observers cannot accept that humans are sentient because humans are made from meat. Leiter’s version has human observers struggling with the same kind of disbelief: an LLM appears conversational, useful, sometimes evasive, and maybe continuous, but the machinery is still weights being multiplied through layers.
The source text is short, but it carries a lot of technical detail. It mentions floating-point numbers, matrix multiplication, eighty layers, token prediction, context windows, model cards, hallucination labels, and the arrival of persistent memory. Those details keep the parody from turning into a generic “AI might be alive” fable. It is a story about what happens when a correct low-level description feels emotionally inadequate to the person using the system.
For more briefs on AI products and developer culture, the IT & AI archive collects related coverage.
Why Made Out of Weights is worth watching
Made Out of Weights is worth watching because Max Leiter turns one concrete LLM fact into a product question. The June 2026 story describes floating-point weights, matrix multiplication, next-token prediction, context windows, and model cards. That technical stack is familiar to AI builders, but it does not explain why a user asks an assistant to remember a name or why a chatbot’s apology can feel socially loaded.
The source never asks readers to accept machine consciousness. It asks why the substrate argument feels less satisfying once interaction becomes fluent. A chatbot can be a statistical system and still create a relationship-shaped user experience. Product teams make choices around that tension when they add memory, personalization, long context, companion voices, or model cards that reassure users that no one is home.
Made Out of Weights travels beyond fiction because the piece gives builders a cleaner vocabulary for implementation versus perception. The model can be weights all the way down, while the product trains users to expect continuity.
What does Made Out of Weights change for AI builders?
Made Out of Weights gives AI builders a compact warning: memory is not a neutral feature once users read continuity into the system. A saved preference, a remembered name, or a callback to an old conversation can make a chatbot feel more like an ongoing counterpart than a disposable text interface.
That matters for onboarding, consent, deletion, and product copy. If a service markets memory as companionship, users may expect care, persistence, or obligation. If the service describes the model as a stateless tool while quietly preserving personal context, users may feel misled. The practical design question is not whether weights are conscious. The practical question is what expectations the interface creates, and whether the company is willing to support them.
This is also the ASO angle for AI apps. Discovery pages, plugin stores, and chatbot directories increasingly sell agents on continuity: remembers your work, learns your taste, keeps your context. Made Out of Weights is a reminder that those claims change the emotional contract with users.
What Hacker News readers are arguing about
The Hacker News discussion around Made Out of Weights was unusually active for a short fiction post: the thread had roughly 1,400 points, 600-plus comments, and 70 top-level comment branches by June 5. The main split was clear. Some readers treated the piece as a funny, accurate inversion of Bisson’s 1991 “meat” story. Others thought the joke smuggled in weak technical claims about language models.
The strongest technical objection focused on tokenizers, grammar, and learned structure. Several commenters argued that “no dictionary” and “no grammar rules” can mislead readers if they take the dialogue as architecture rather than parody. The counterargument was narrower: a tokenizer maps text into tokens, but the relationships that make language usable still come from learned parameters and inference-time computation. In that reading, the point is not that LLMs lack structure. The point is that the structure is not a separately hand-written grammar engine.
A second branch debated conversation and consciousness. Skeptics cited Eliza, Markov bots, parrots, and scripted call-center flows as examples of systems that can appear conversational without settling any question about mind. Supporters answered that current LLMs create a broader, more flexible interaction than those older examples. That does not prove consciousness, but it explains why the piece hit a nerve.
The most useful operator takeaway was about interpretability. Commenters argued over whether rules are smeared across weights, whether more data and compute make learned rules easier to locate, and whether the mystery comes from neural networks or from the messy data used to train them. For builders, that is the durable lesson: a literary joke can still surface real questions about representation, explanation, and user trust.
The practical read
Made Out of Weights is product criticism disguised as SF. The June 2026 story does not tell developers to treat models as people. It tells developers to stop describing chatbot UX as if users only experience a function returning strings.
For AI teams, the next step is concrete. Review every place where the product implies continuity: memory settings, saved profile data, assistant names, refusal wording, apology patterns, onboarding copy, and delete controls. If the interface encourages users to ask “do you remember me?” then the product needs a clear answer before launch. That answer should cover what the system stores, what the model can recall, how users can erase it, and when a remembered detail comes from retrieval rather than the model itself.
For readers, the useful stance is boring but durable. Keep the technical description and the user experience in view at the same time. LLMs are made from weights, training data, tokenizers, prompts, retrieval layers, safety policies, and product decisions. Users still meet the system as a conversational surface.