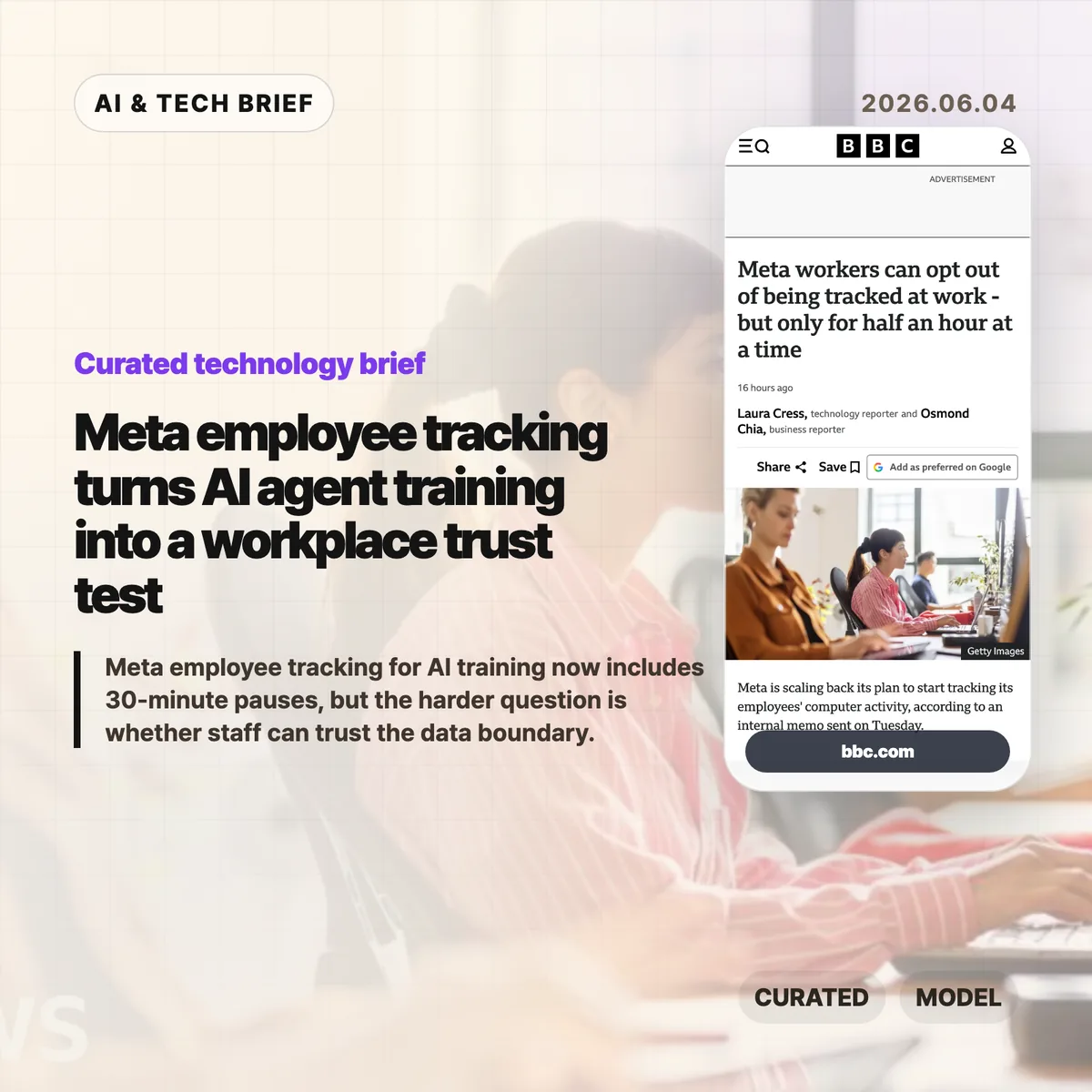
Meta employee tracking moved from an internal AI training plan into a public workplace privacy fight after the company added limited controls for staff in June 2026. BBC News reported that Meta now lets employees pause collection of clicks and keystrokes for up to 30 minutes at a time, with a separate path to request a full exemption. That narrow opt-out raises the harder question for AI agent teams: how much real workplace behavior can a company collect before model training starts to feel like surveillance?
Table of Contents
The short version
- Meta’s Model Capability Initiative was designed to collect employees’ keystrokes and mouse clicks so AI models could learn how people use computers at work, according to BBC News.
- In June 2026, Meta added a pause control that can stop collection for up to 30 minutes at a time, plus a process for full exemptions.
- BBC News reported that a staff petition against the program drew more than 1,500 signatures, after workers raised concerns about personal data, battery life, and control over capture.
- Agent builders should treat consent, scope, retention, redaction, and opt-out records as product requirements, not policy cleanup after employees complain.
What happened
Meta scaled back part of an internal plan to record employees’ computer activity for AI training in June 2026, according to BBC News, which cited Reuters reporting and an internal memo. The system, called the Model Capability Initiative, was meant to capture examples of how staff use computers so Meta’s models could learn everyday software workflows. Meta had previously told the BBC that agents need real examples if they are going to help people complete tasks on computers.
The new controls let employees pause collection for “up to 30 minutes at a time” and request an exemption from the initiative. Meta also said the data would not be used for another purpose and that safeguards were in place for sensitive content. Staff were still uneasy. The BBC story says more than 1,500 employees signed a petition, while named and unnamed workers raised concerns about personal data on work devices, battery life, and the feeling that AI was being pushed into daily work without enough trust.
Why Meta employee tracking is worth watching
Meta employee tracking is worth watching because it exposes the data trade-off behind computer-using AI agents. A chatbot can learn from documents and conversations. An agent that operates software needs examples of clicking through tools, filling forms, switching windows, correcting errors, and recovering when apps behave oddly. Those traces are closer to how work actually happens, which makes them useful for training and more sensitive than ordinary product analytics.
For enterprise AI teams, the Meta case turns product design into labor policy. A pause button sounds like user control, but a 30-minute window does not answer who can see pause events, whether managers can infer that someone opted out, how long raw traces are stored, or how personal material on a work machine is filtered before training. Teams building similar systems need to write those boundaries before collection starts, not after employees organize against it. For more IT and AI coverage, see the IT & AI archive.
What does Meta employee tracking change for agent builders?
Meta employee tracking gives agent builders a practical warning: workflow data is valuable because it is messy, and that mess includes private context. A clickstream can reveal source code, customer records, HR screens, medical details, private messages, passwords in bad workflows, or simply the rhythm of a person’s day. Even if a company promises to use the data only for model training, employees may hear a second promise that was never made: that the same data will not affect performance reviews, investigations, or future automation decisions.
Builders of enterprise agents should treat pause, opt-out, redaction, retention, audit logs, and purpose limits as core product requirements. The minimum viable policy is not a banner that says collection is happening. Teams need plain rules for which apps are in scope, which fields are masked, who can inspect raw traces, when data is deleted, and how an employee can challenge a capture. That matters for adoption as much as model quality.
What Hacker News readers are arguing about
The Hacker News discussion was overwhelmingly skeptical, with most of the heat aimed at the gap between a 30-minute pause and meaningful control. Several commenters treated the pause button as dark comedy: if employees need privacy for payroll, HR, legal work, or personal material on a work device, half an hour feels arbitrary. A repeated worry was that opt-outs themselves could become a management signal, even if Meta never says that is the purpose.
The more useful builder argument in the thread was about culture. One commenter noted that modern companies can already use Jira, GitHub, chat logs, and LLM summaries to build a picture of an employee’s work. In that view, the danger is less the existence of telemetry and more whether leadership has earned enough trust to use it narrowly. Other comments were harsher, comparing the policy to surveillance tech being turned inward on the people who build it. It is a discussion, not evidence, but it captures why technical safeguards will not carry a workplace AI program if employees expect the data to be used against them.
The practical read
Teams building workplace AI agents should separate three questions before copying Meta’s approach. First, what behavior data is genuinely needed to improve the model? Second, can the same goal be met with synthetic tasks, volunteer sessions, narrow app-specific traces, or redacted recordings instead of broad background collection? Third, what would employees see if they audited the system after the fact?
The 30-minute pause is a useful reminder that control surfaces can look generous while still feeling weak. A stronger design would make collection visible, narrow, revocable, and auditable. It would also protect the act of opting out, because a privacy control that creates a performance signal is not much of a privacy control. AI agent teams should test their data policy with the same seriousness they give latency, benchmarks, and tool reliability.